Your AI Strategy Will Fail Without This One Foundation
Sector: AI + Data
Author: Nisarg Mehta
Date: 04/13/2026

Every boardroom is talking about artificial intelligence. Budgets are being reallocated, pilots
are being announced, and executives are under enormous pressure to “do something with AI, now.” But here is the uncomfortable truth most vendors will never put in their pitch deck: the organizations generating extraordinary, repeatable results from AI are not winning because of which model they chose, which platform they licensed, or how much compute they provisioned. They are winning because they fixed their data first.
This distinction matters more than almost anything else being written about AI in 2025. When organizations rush to deploy AI on top of fragmented, inconsistent, or incomplete data, and most do, they are not simply getting mediocre results. They are amplifying their existing errors, encoding their existing biases, and scaling their existing blind spots. Faster. At greater volume. With more automation than any human process ever allowed.
Artificial Intelligence is at its fundamental level, a pattern amplifier. It finds the patterns that already exist in your data and makes them actionable at scale. When those underlying patterns are clean and representative of reality, AI becomes a genuinely transformative business asset. When those patterns are noisy, incomplete, or systemically biased, because the data that created them was, AI faithfully reproduces and scales all of that noise, inconsistency, and bias. The model has no way to know the difference.
This analysis maps out five critical pillars through which AI delivers measurable, documented business value, across healthcare, manufacturing, and retail, and shows, with hard numbers drawn from McKinsey Global Institute, IBM Research, Deloitte, Accenture, Bain, Medallia, and industry case studies, exactly how data accuracy determines whether you reach the extraordinary high end or the deeply disappointing low end of those outcomes. The gap between those two ends is not 10 or 20 percent. In some cases, it is the difference between an 87% defect reduction and a 20% one, the same model, the same algorithm, the same deployment team. The only variable is data quality.
Why Data Quality Doesn't Just Matter - It Determines Everything
Most executives, when they think about the relationship between data quality and AI performance, imagine something roughly linear. Clean up 20 percent of your data problems, get 20 percent better AI results. Invest in data governance, see a proportional return. It seems reasonable. It is also fundamentally wrong, and the misunderstanding is costing organizations billions in wasted AI investment every year.
The relationship between data quality and AI performance is exponential, not linear. A 20% improvement in data completeness and accuracy can drive a 35–60% boost in model performance because machine learning relies on pattern recognition across complex datasets.
This is where data engineering becomes critical, building clean, consistent, and well-structured data pipelines ensures reliable inputs, prevents pattern corruption, and enables AI models to deliver accurate, scalable results.
“AI is only as intelligent as the data you teach it with. Organizations that invest in data quality see AI returns that are three to five times higher than those that don’t.”
— McKinsey Global Institute, 2024
Consider a hospital deploying an AI model to predict patient readmissions, one of the highest-value healthcare AI use cases, with direct implications for patient outcomes, resource allocation, and regulatory penalties. If that hospital’s electronic health records contain 30 percent missing values, which, critically, is not an extreme scenario but a common reality across healthcare systems globally, its readmission prediction model accuracy may plateau around 65 percent. That sounds acceptable until you consider what it means in practice: one in three predictions is wrong, and the care teams making resource decisions based on those predictions have no reliable way to know which third.
Clean that same data to 95 percent completeness, without changing the model, the algorithm, or the team, and the accuracy of those same predictions climbs above 85 percent. That 20-point swing is not an abstraction. It translates directly into fewer preventable readmissions, better patient outcomes, and tens of millions of dollars in avoided costs and penalties. The model did not change. Only the data did.
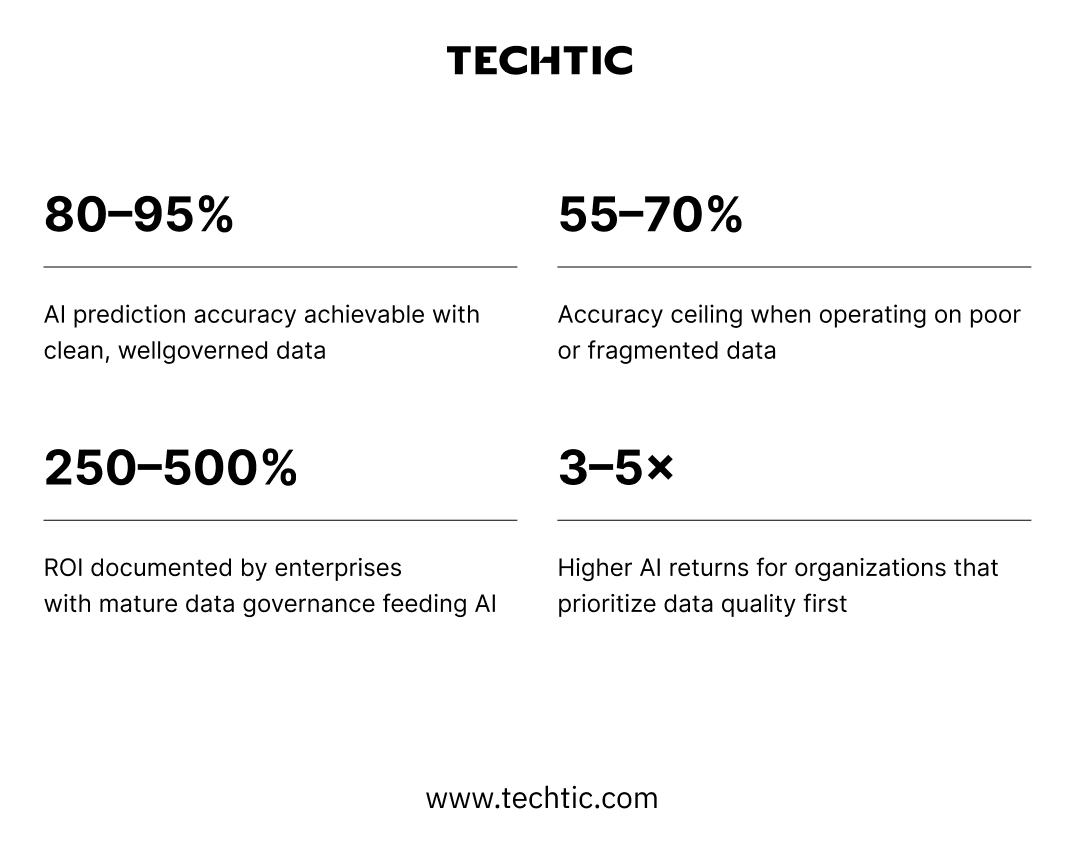
This pattern holds across every industry examined. Manufacturing plants using AI for defect detection see 30 to 87 percent defect reductions with clean sensor data, and 15 to 20 percent reductions with poor data. Retailers using AI for demand forecasting see 10 to 15 percent accuracy improvements with governed data, and marginal or negative ROI with fragmented transaction records. The model is constant. The data is the variable. And the data is everything.
The Hidden Cost Nobody Talks About
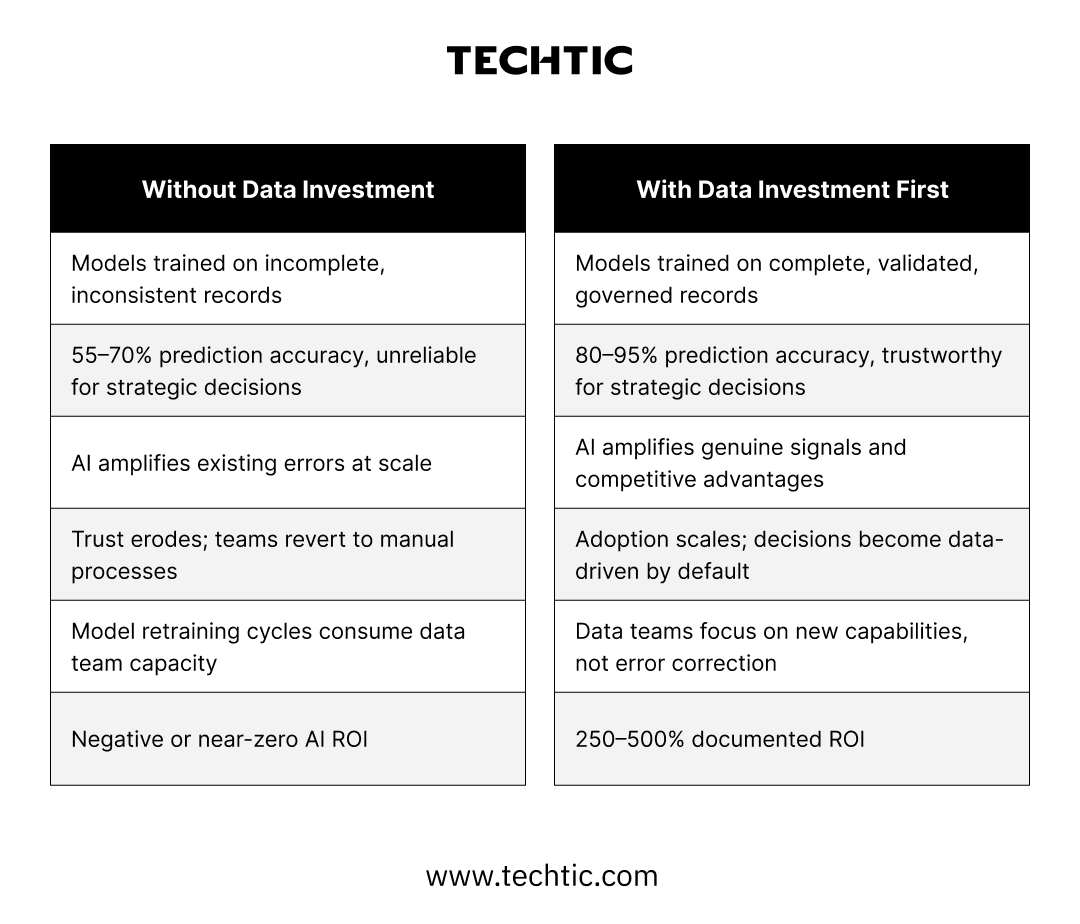
Beyond the direct performance gap, poor data quality imposes a second, less visible cost that compounds over time: eroded organizational trust in AI. When models produce unreliable outputs, even occasionally, business users stop relying on them. Decision-makers revert to gut instinct. Data teams spend enormous cycles chasing errors and retraining models rather than building new capabilities. The initial cost of the poor data becomes a recurring tax on every AI initiative the organization runs.
Organizations at data maturity Level 1, siloed, ungoverned data, frequently report that their AI pilots technically “worked” but were never adopted at scale. The model was fine. The data wasn’t trustworthy enough for anyone to stake a real decision on. That is not an AI failure. That is a data failure with an AI label on it.
The AI Value Chain: Where Data Creates - or Destroys - Value
Effective AI deployment is not a single event. It is a sequential five-stage value chain where the output of each stage becomes the input of the next. Understanding this chain is critical because it clarifies something most AI strategies miss: you cannot compensate for weakness in an early stage by optimizing a later one. A Level 4 model trained on Level 1 data will perform like a Level 1 model. There is no workaround, no patch, and no vendor who can sell you one.
Stage 01 - Raw Data Sources
Sensors, electronic health records, point-of-sale transactions, supplier feeds, customer behavior logs, IoT streams. This is where data quality is either built in or permanently compromised. Errors introduced here, missing fields, miscalibrated sensors, inconsistent formats, cannot be fully recovered downstream regardless of how sophisticated the downstream processing becomes. The single most cost-effective place to invest in data quality is here, at the source, before data accumulates technical debt.
Stage 02 - Data Governance Layer
Cleansing, normalization, completeness checks, deduplication, schema validation, master data management, and lineage tracking. This is the investment most organizations systematically underestimate or skip entirely, and the exact reason their AI pilots disappoint at scale. Moving from an ad hoc cleanup process to a real-time governance pipeline is the single highest-leverage AI investment most organizations can make in 2025.
Stage 03 - AI Model Training
Machine learning models learn from labeled, structured historical data. This stage is where the commonly cited principle of “garbage in, garbage out” is most visibly and consequentially true. A model trained on noisy data does not learn to be cautious or conservative about that noise. It learns to treat the noise as signal, and encodes that misunderstanding permanently into every prediction it makes. No amount of hyperparameter tuning or architecture selection corrects for training data that does not reflect reality.
Stage 04 - Prediction Accuracy
The outputs that drive real business decisions, readmission risk scores, defect probability flags, demand forecasts, pricing recommendations. With clean, governed data feeding well-trained models, accuracy of 80 to 95 percent is achievable and documented across industries. With poor data, 55 to 70 percent is the realistic ceiling. That gap determines the quality of every downstream decision the organization makes using AI outputs.
Stage 05 - Business Outcomes
Cost reduction, revenue growth, operational efficiency gains, supply chain resilience, and compounding competitive advantage. This is where the data quality investment finally becomes visible on the P&L, but only to organizations that made the investment in Stages 01 and 02 first. For those that did, 250 to 500 percent ROI is documented. For those that did not, Stage 05 delivers frustration, budget debates, and a growing conviction that AI was overhyped.
The Data Maturity Ladder: Know Exactly Where Your Organization Stands
Before any organization can design an effective AI strategy, it needs an honest assessment of where it sits on the data maturity ladder. This is not a technology assessment, it is an organizational honesty exercise. The four levels below describe real patterns observed across industries, and where you land determines what AI can realistically deliver for you right now.
Level 1 — Siloed data~55% AI accuracy
Data lives in disconnected, incompatible systems with no shared schema, no unified identifiers, and no governance policies. Sales data and CRM data cannot be reliably joined. Sensor data is not linked to maintenance records. EHR systems don’t talk to billing systems. AI models at this level are trained on contradictory signals from incompatible sources and produce outputs that business users quickly learn not to trust. Most organizations running AI pilots that “didn’t work” were operating at Level 1 and didn’t know it.
Level 2 — Integrated data~68% AI accuracy
Systems are connected, through ETL pipelines, data warehouses, or data lakes, but not consistently governed. Data flows between systems, but inconsistencies, duplicates, and schema mismatches persist. Some AI use cases work reasonably well; others fail unexpectedly. Results are better than Level 1 but not reliable enough to stake strategic decisions on. Many organizations believe they are at Level 3 when they are actually at Level 2, a dangerous place to be when scaling AI investment.
Level 3 — Governed data~80% AI accuracy
Real data ownership is established. Validation pipelines run continuously. Master data management is operational. Schema standards are enforced at ingestion. Data lineage is tracked so that when a model produces a surprising output, teams can trace it back to its source. AI becomes reliably useful at this level, trustworthy enough for operational decisions, if not yet fully optimized for strategic ones. This is the minimum viable foundation for scaling AI investment with confidence.
Level 4 — Optimized data~93% AI accuracy
Real-time validation, continuous model feedback loops, and automated anomaly detection are all operational. Data accountability is a cultural value, embedded in job descriptions, performance reviews, and team incentives, not just a technical policy. AI at this level becomes a structural competitive advantage, compounding value every quarter as models improve on increasingly high-quality data. This is the level at which the 250 to 500 percent documented ROI figures are achieved. Only a minority of organizations globally operate here today, which is precisely why those that do are pulling so far ahead.
“The gap between Level 1 and Level 4 is not measured in percentage points of accuracy. It is measured in whether AI is generating profit or burning cash, and whether that gap compounds or closes by 2030.”
— IBM Research / Articledge, 2025
The critical insight: moving from Level 1 to Level 3 is a 18-to-36-month organizational journey for most companies, not because the technology is hard, but because it requires cross-functional accountability structures that most organizations were not designed to produce. Those who started that journey in 2022 or 2023 are now reaping the returns. Those who are starting today are 18 months behind organizations that are already running optimized AI at Level 3 and 4.
Five Pillars of AI Business Value - When the Data Is Right
AI creates real, documented business value across five distinct dimensions. Each pillar builds on the one before it. The data requirements deepen as you progress from Pillar 1 through Pillar 5. And critically, every number in this section represents what is achievable with a strong data foundation. Organizations without that foundation will see materially lower results, longer payback periods, and higher failure rates across every pillar.
Pillar One - Customer Experience - From Reactive to Anticipatory
AI transforms customer interactions from reactive to anticipatory, but only when customer data is unified, accurate, and complete across every touchpoint. This is more difficult than it sounds. Most organizations have customer data fragmented across CRM platforms, e-commerce systems, loyalty programs, call center logs, and marketing automation tools, each with its own schema, its own definition of a “customer,” and its own data quality standards.
The consequence is familiar: AI generates generic recommendations that customers ignore, chatbots that fail to understand context, and personalization engines that surface products customers already bought last week. None of this is an AI failure. It is a data integration failure wearing an AI costume.
When organizations invest in unified customer data, a single source of truth that reconciles identity across systems, captures behavioral signals in real time, and validates completeness before it feeds models, the results shift dramatically. Retailers with clean, behaviorally rich customer data are achieving 6× higher transaction rates from AI-driven recommendations. Healthcare systems with unified patient records are cutting administrative burden by 40 percent while simultaneously improving patient satisfaction scores above 72 percent. These are not pilot project numbers. They are documented production outcomes at scale.
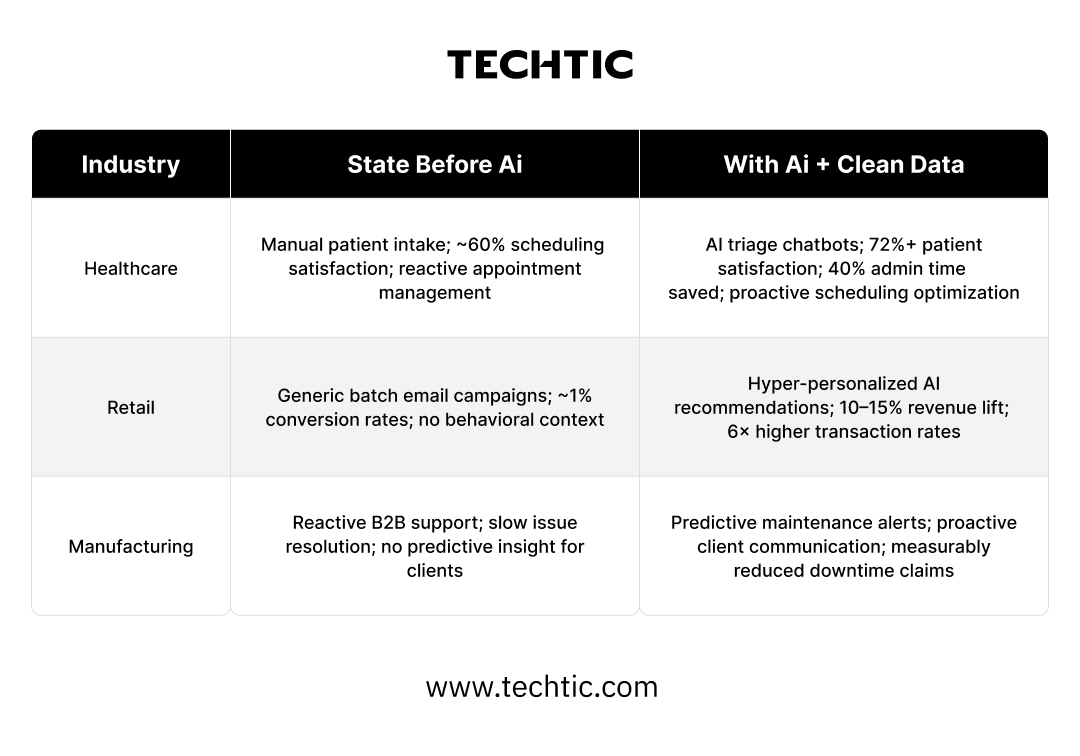
Industry benchmark: Leaders in AI-driven personalization are 3× more likely to achieve 10%+ annual revenue growth than organizations still operating with fragmented customer data, and that gap is widening every year.
Pillar Two - Operations - The Most Immediate, Measurable ROI
Operational AI, predictive maintenance, quality inspection, staff scheduling, logistics optimization, delivers the fastest and most measurable returns of any AI use case. And uniquely among the five pillars, the data requirements are often the most achievable: high-frequency, high-accuracy sensor and operational data that already exists in many organizations, waiting to be governed and leveraged.
The range of outcomes in this pillar is striking, and directly illustrative of the data quality effect. Manufacturing plants with well-governed, real-time sensor data feeding computer vision models are achieving 87 percent defect reduction rates. Plants attempting the same use case with poorly calibrated, inconsistently labeled sensor data are seeing 20 to 30 percent improvements. The technology is identical. The data quality is the variable. A 20 percent defect reduction is a line item. An 87 percent defect reduction is a transformation that redefines quality benchmarks for an entire industry segment.
In retail, the operational AI story is about simultaneous inventory and service-level optimization, a combination that was previously treated as a fundamental trade-off. Organizations with clean logistics and demand data are achieving 35 percent inventory reductions and 65 percent service level improvements at the same time, because AI can identify and act on the granular patterns in demand variability that human planners cannot.
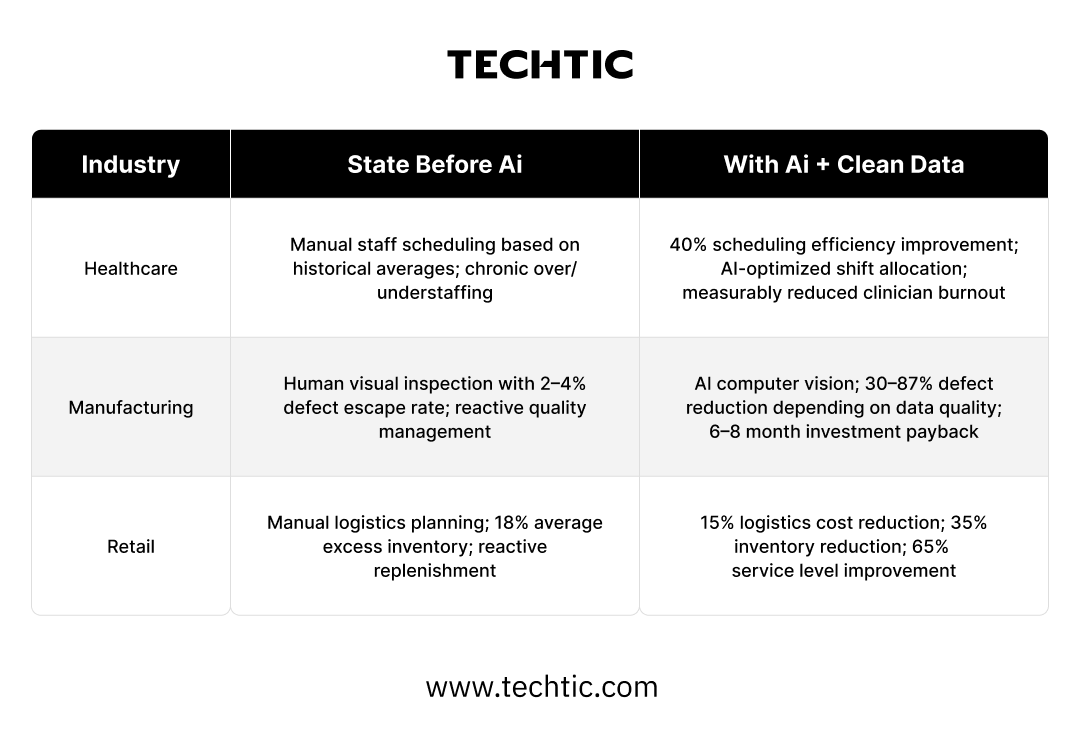
Critical caveat: The 6–8 month payback period for manufacturing AI quality control is achievable with clean, real-time sensor data. Organizations with poorly governed sensor data should budget 18–24+ months for payback, and higher failure rates for initial deployments.
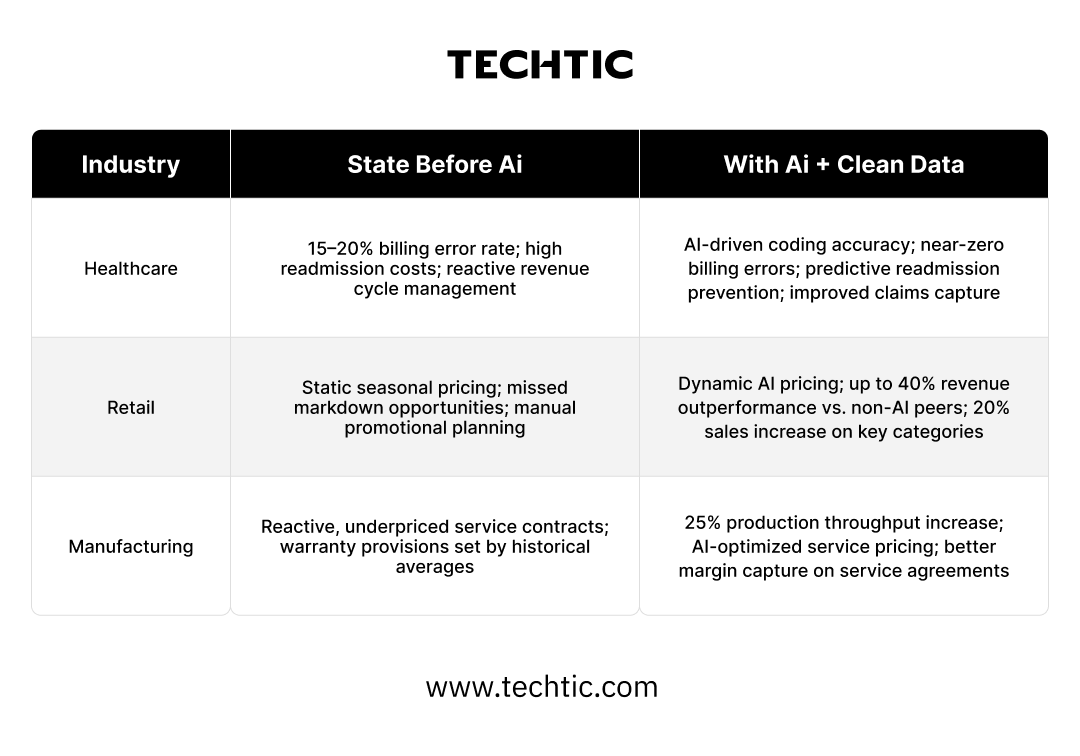
Pillar Three - Revenue Optimization, The Deepest Data Requirements
Revenue AI – dynamic pricing, demand forecasting, contract optimization, upsell and cross-sell timing, billing accuracy, requires the strongest data foundation of any pillar. These applications sit at the intersection of multiple data domains: transactional history, customer behavior, market signals, pricing history, competitive intelligence, and cost data. Weakness in any of these domains limits the ceiling of what revenue AI can deliver.
The stakes in this pillar are proportionally higher. Retailers with clean pricing and transaction data feeding dynamic pricing models are generating up to 40 percent more revenue than non-AI peers, a structural market share shift, not a marginal efficiency improvement.
Healthcare organizations using AI-driven billing and coding accuracy are eliminating billing error rates that were previously running at 15 to 20 percent, directly recovering revenue that was systematically being lost. In manufacturing, AI-optimized service contracts and warranty pricing are unlocking 25 percent throughput improvements alongside better margin capture on service agreements.
The warning here is equally important: revenue AI deployed on poor data does not simply underperform. It can actively destroy value, recommending prices that erode margins, forecasting demand incorrectly and driving overproduction, or misfiling claims in ways that trigger regulatory scrutiny. The downside of poorly-governed revenue AI is not zero ROI. It can be negative ROI at scale.
Risk note: Revenue AI has the highest potential upside and the highest potential downside in this framework. Organizations with data maturity below Level 2 should approach revenue AI applications with significant caution and narrow initial scope.
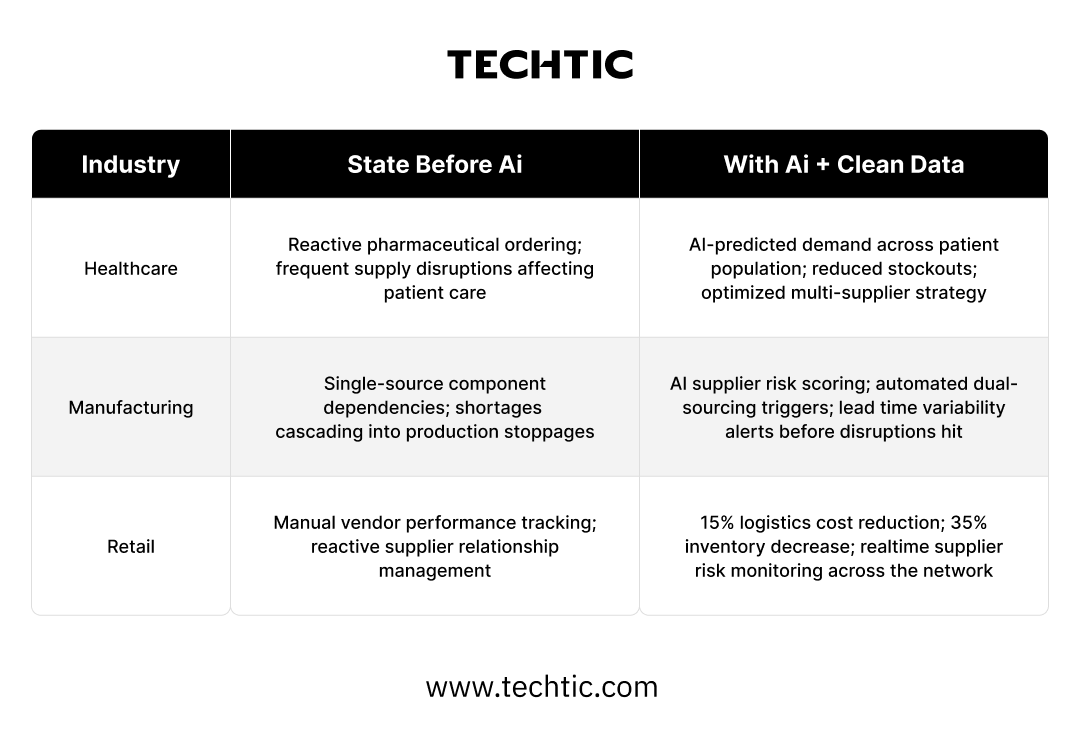
Pillar Four - Sourcing & Supply Chain - Where Supplier Data Separates Leaders
Sourcing AI sits at the intersection of supplier data quality, logistics accuracy, and demand signal fidelity. It is also the pillar where the consequences of poor data are most dramatically visible in real time, because supply chain failures cascade publicly and expensively. The COVID-era supply chain crisis, which exposed single-source dependencies and lack of real-time supplier visibility across almost every industry, reset executive priorities permanently. 86 percent of manufacturing executives now identify AI-led supply chain resilience as a top-three strategic priority through 2030.
Organizations with poor supplier data integration are making procurement and risk decisions based on a fraction of the available signals. They discover supply disruptions after they have already cascaded into production delays and revenue losses. They carry excess safety stock because they cannot trust demand signals enough to run lean. Those with unified, real-time sourcing data are achieving 35 percent inventory reductions while simultaneously activating AI-driven risk scoring, dual-sourcing triggers, and lead time variability alerts, turning supply chain from a perennial operational headache into a documented competitive advantage.
Post-pandemic reality: Supply chain AI is now a board-level priority in most industries. Organizations that have not invested in unified supplier data are structurally vulnerable to disruptions their AI-equipped competitors will navigate smoothly.
Pillar Five - Predictive Analytics - Where the Data Investment Becomes a Structural Moat
This is where everything clicks, and where the gap between data-mature and data-immature organizations becomes structurally difficult to close. Pillars 1 through 4 are operational advantages: meaningful, measurable, and valuable. Pillar 5 is a fundamentally different category of advantage: genuine predictive foresight that enables organizations to make proactive decisions instead of reactive ones, compounding every quarter.
Organizations that built strong data foundations across Pillars 1 through 4 accumulate years of high-quality, validated operational, financial, and market data. AI models fed by that historical depth can forecast with 80 to 95 percent accuracy across cost, revenue, demand, and market dynamics, dramatically outperforming the statistical models and human judgment processes that most organizations still rely on for strategic planning.
The moat effect is real and compounding. An organization that has been collecting high-quality operational data for three years has a training data advantage that a competitor starting today cannot buy their way out of quickly. The models trained on that richer history will be more accurate. Those more accurate models will generate better decisions. Better decisions will generate better outcomes. Better outcomes will generate more data. The cycle reinforces itself, every quarter, every year, widening the gap between those who invested early and those who are still asking whether they should.
Pillar 5 is not available to organizations that skipped Pillars 1 through 4. It is the exclusive reward for those who made the patient, unglamorous investment in data quality infrastructure first, and the most powerful argument for starting that investment today rather than waiting for the technology to mature further. The technology is already mature. The data is the constraint.
The compounding moat: Every quarter an organization operates at Level 3–4 data maturity widens its AI advantage over competitors at Level 1–2. By 2030, this gap will be structurally difficult to close for late movers, because the data history required to train high-accuracy long-range forecasting models takes years to accumulate, and cannot be manufactured retroactively.
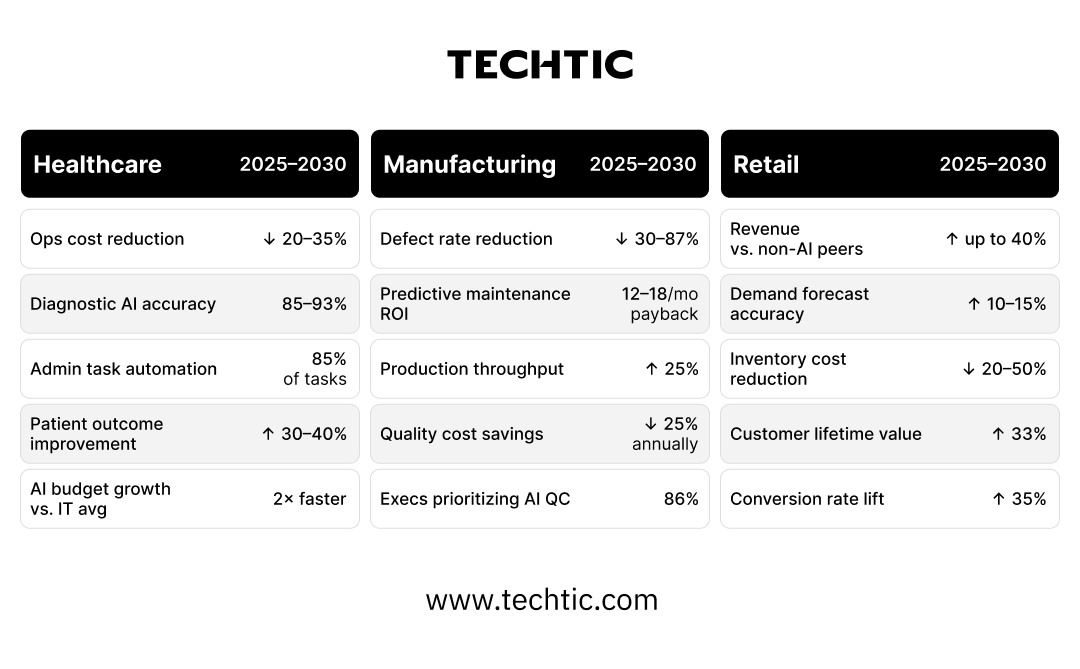
2025–2030 Industry Outlook: What the Numbers Say
For organizations making the data investment now, here is what the documented evidence suggests the next five years can deliver, across the three industries where the data-first AI pattern is generating the clearest and most consistent evidence base.
“The next five years will not separate AI adopters from non-adopters. They will separate organizations with mature data foundations from those still trying to clean up the technical debt they built over the last decade.”
— Industry Intelligence Series, 2025
These figures represent the high end of what is achievable, and they are achievable. But not universally and not automatically. They are achievable specifically by organizations that have built the data foundation described across Sections 01 through 03. For organizations operating at Level 1 or Level 2 data maturity, these numbers describe the opportunity they are leaving on the table, not the outcomes their current infrastructure can deliver.

The Bottom Line: The AI Race Is a Data Race
The AI adoption race is not primarily a technology race. It is a data governance race. The organizations pulling ahead are not necessarily the ones with the largest AI budgets, the most prestigious technology partners, or the most aggressive deployment timelines. They are the organizations that invested, quietly, patiently, and often years before their competitors, in the unglamorous infrastructure of data quality: unified data models, real-time validation pipelines, master data management, clear ownership accountability, and a culture where data quality is a first-class organizational value rather than an IT department afterthought.
Every extraordinary number in this analysis, 87 percent defect reduction, 40 percent revenue outperformance, 93 percent diagnostic accuracy, 250 to 500 percent ROI, is achievable. They are not marketing claims. They are documented outcomes from organizations operating at Level 3 and Level 4 data maturity with AI running across multiple pillars simultaneously. But not one of those outcomes is achievable by deploying AI on top of fragmented, inconsistent, incomplete data. Every single one of those paths runs directly through a data quality investment made first.
The next five years will not be kind to organizations that treat data governance as a back-office function and AI deployment as a front-office priority. They will be extraordinary for organizations that understood, early, that you cannot separate the two. Data is the foundation. AI is the multiplier. And a multiplier applied to a broken foundation produces a broken result, faster, at greater scale, with more confidence than ever before.
FAQs
Q. What does data quality mean in practical terms?
Data quality is defined by four key dimensions: completeness, accuracy, consistency, and
Timeliness, ensuring data is reliable, unified, and up-to-date for decision-making.
Most organizations struggle due to siloed systems, inconsistent definitions, and lack of data accountability.
Q. Why do most enterprise AI strategies fail despite using advanced models?
Most enterprise AI strategies fail not because of weak models, but because of poor data foundations. When data is fragmented, inconsistent, or incomplete, even the most advanced AI systems produce unreliable outputs. Successful AI depends on clean, connected, and governed data, not just powerful algorithms.
Q. What is the biggest mistake companies make when adopting AI?
The biggest mistake is focusing on AI tools instead of data infrastructure. Many organizations invest in models, dashboards, or automation without fixing data silos, quality issues, and governance gaps, leading to failed AI initiatives and low ROI.
Q. How does poor data quality impact AI performance?
Poor data quality directly limits AI accuracy, often capping it at 55–68%, regardless of the model used. In contrast, high-quality, governed data can boost AI accuracy to 80–95% and unlock significant business value, including higher revenue and better decision-making.
Q. What is data maturity, and why is it critical for AI success?
Data maturity refers to how well an organization manages, integrates, and governs its data. Organizations with low maturity (siloed data) struggle with unreliable AI, while those with high maturity (governed and optimized data) achieve scalable, high-impact AI outcomes and long-term competitive advantage.



